With 25 years of experience in the document imaging industry, there have been many changes but for the most part, it consists of scanning or uploading images to storage to be retrieved at a later time. Scanned or uploaded images themselves are just pictures and there is nothing that you can search for except possibly the filename and or a date when uploaded or created. This means that to make the document retrievable you need to have them indexed. Indexing is the most expensive and resource-draining component of document imaging. We saw a need for a new way of document management. We have developed a way to streamline this process so that you never have to index again.
ScanSearch
Who We Are


Why ScanSearch
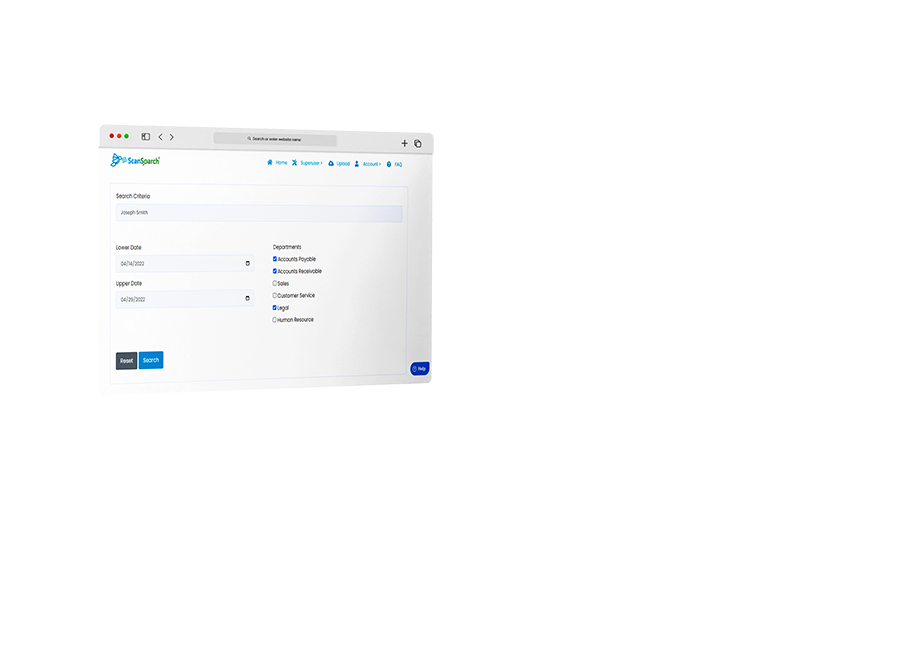
The new product that we are providing does away with the entire indexing process! We simply OCR every word on the document and let you search on that in a full-text manner. For example, if you want to find an invoice that has an invoice number of “INV4573” you would type “INV4573” into the “search” field much like google and it will retrieve the appropriate invoice. We do not need to know that it is an invoice number and certainly do not need to put it into its own field. The rule is we just need to search for what we need. Now, this sounds awfully simple but it literally does not exist out there in the simplistic way that we offer it. Sure, you can piece it together using some of the isolated technology components out there by spending boatloads of dollars and even more on resources but at the moment it is just us. Just us with a kiosk set up for departments and users and our server-side technology that does all the magic.

Mathew Dragatsis, CEO/Founder ScanSearch
Cloud Storage
Upload and securely store all scanned documents with no obligations on our cloud servers.
Seamless Results
Our powerful AI allows you to search anything, any field, immediately, with no manual indexing needed.
Instantly Search
Collect any data element found on your documents upon upload and search for any field instantly.
Tiered Plans
Choose the plan that best suits your exact needs. Plans based on your document flow and business’s demands.
No Indexing
Immediately search any scanned document with no indexing or tagging necessary.
Powered by AI
ScanSearch’s Powerful built-in AI allows you to save hundreds of hours of work not to mention those familiar human errors.